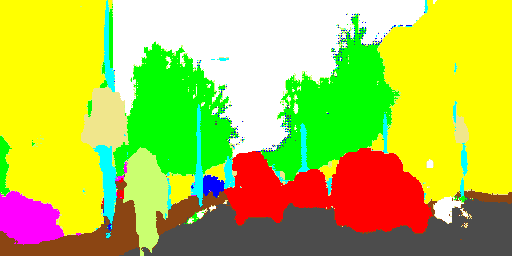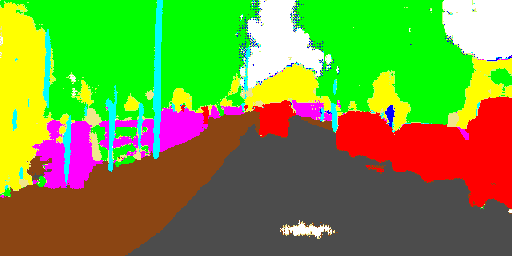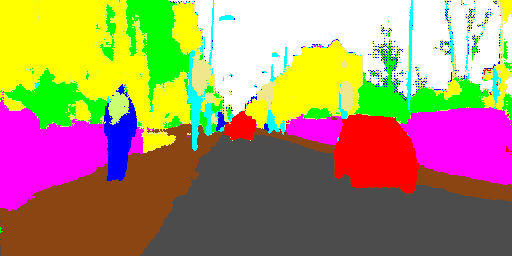
LinkNet is a light deep neural network architecture designed for performing semantic segmentation, which can be used for tasks such as self-driving vehicles, augmented reality, etc. It is capable of giving real-time performance on both GPUs and embedded device such as NVIDIA TX1. This network was designed by members of e-Lab at Purdue University. Its architecture has been explained in the following blocks. LinkNet can process an input image of resolution 1280x720 on TX1 and Titan X at a rate of 2 fps and 19 fps respectively. Training and testing scripts can be accessed using the Github link.
Our proposed deep neural network architecture tries to efficiently share the information learnt by the encoder with the decoder after each downsampling block. This proves to be better than using pooling indices in decoder or just using fully convolutional networks in decoder. Not only this feature forwarding technique gives us good accuracy values, but also enables us to have few parameters in our decoder.
The initial block contains a convolution layer with a kernel size of 7x7 and a stride of 2; followed by a max-pool layer of window size 2x2 and stride of 2. Similarly, the final block performs full convolution taking feature maps from 64 to 32, followed by 2D-convolution. Finally, we use full-convolution as our classifier with a kernel size of 2x2.
More details in paper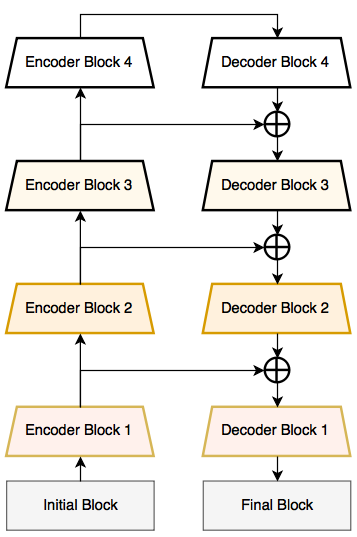
In encoder and decoder block shown in the right, input and output feature maps for each layer can be calculated using: n = 64x2^i, where i the block index. The first encoder block does not perform strided convolution and every convolution layer is followed by batch-normalization and ReLU as non-linearity. The encoder architecture is the same as that of ResNet-18 [3].
| Block # | Encoder | Decoder |
|---|---|---|
| Initial | 64x64x64 | (#Classses)x256x256 |
| 1 | 64x64x64 | 64x64x64 |
| 2 | 128x32x32 | 64x64x64 |
| 3 | 256x16x16 | 128x32x32 |
| 4 | 512x8x8 | 256x16x16 |



This work was partly supported by the Office of Naval Research (ONR) grants N00014-12-1-0167, N00014-15-1-2791 and MURI N00014-10-1-0278. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the TX1, Titan X GPUs used for this research.
[1] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmentation and recognition using structure from motion point clouds,” in ECCV (1), 2008, pp. 44–57.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” arXiv preprint arXiv:1512.03385, 2015.